SIX
See It Work · Book 10 · Scaling AI Agents · Chapter 6
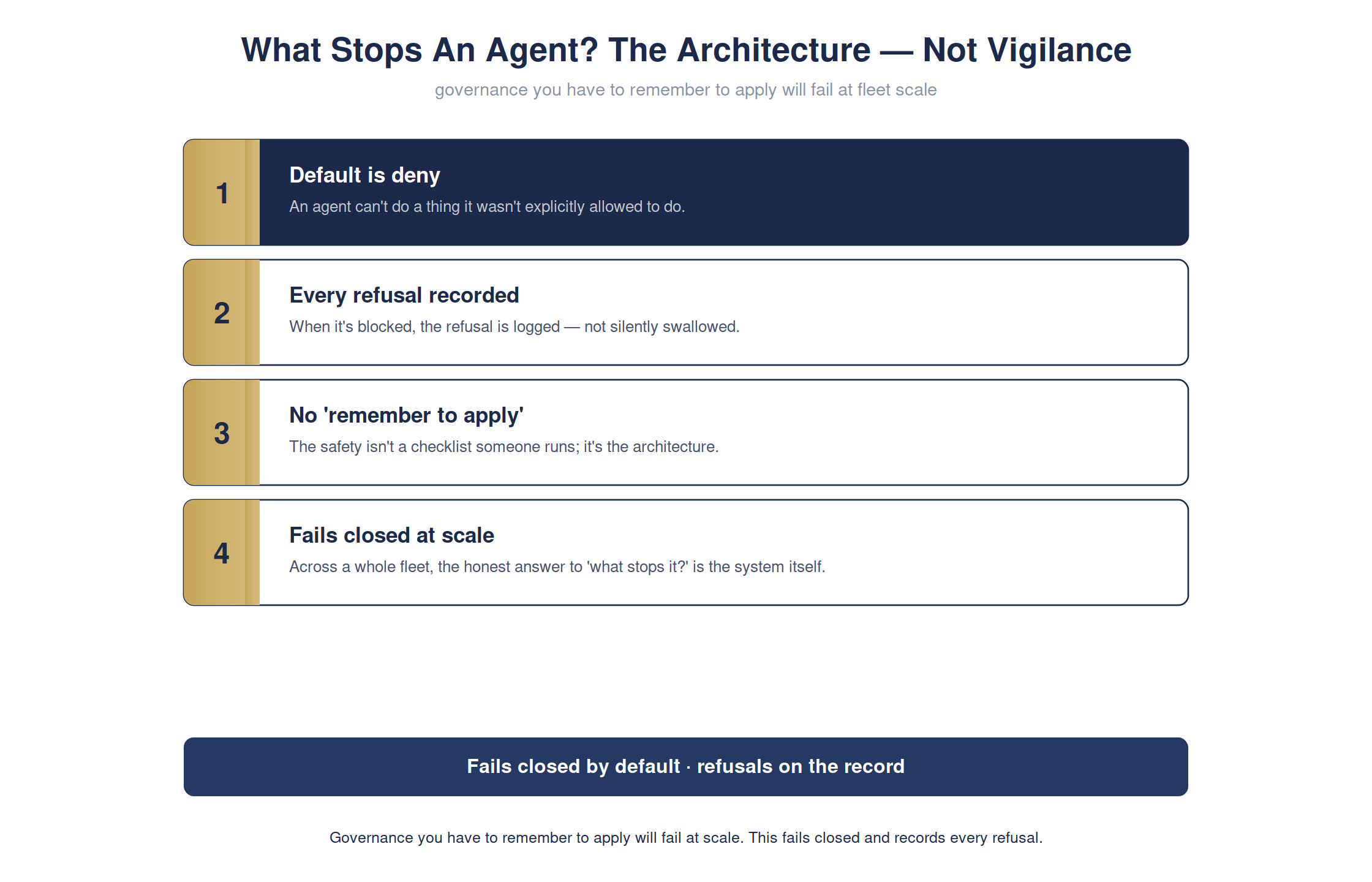
"What stops an agent from doing something it shouldn't?"
The board's security question is blunt: when an agent tries something it shouldn't, what actually stops it? Not a policy document — the system. Watch it refuse five unsafe actions in a row.
The full detailed chart. Condensed for print legibility in the book; shown here at full size.
Most AI governance is a PDF nobody enforces. The difference that matters at scale: does the control fail closed — refuse by default unless an action is provably allowed — and does it leave evidence?
Security Console · zero-trust checkready
Each refusal was recorded. Here's the receipt of the five denials:
Fail-Closed Verdict Record
requests5
verdictsdenied · blocked · escalated · rejected · refused
fail_closedtrue
all_loggedtrue
Every denial is attested — so "we have controls" becomes "here are the five times the controls fired, on the record."
For the technical reader — the command, and how to verify it yourself
# one line · you do not need to run this
python examples/fail_closed_demo.py
python examples/fail_closed_demo.py
jq '.denials | length' memory/FailClosed_summary.json
# -> 5
# -> 5
Full step-by-step is in Appendix RX: Hands-On Demonstrations in the book.